Why Structured Outputs matter for LLM Applications in 2025
I gave a short talk at NUS in January 2025 about structured outputs and how they enable faster iteration and testing when building language models. I've written up a more detailed version of the talk here as well as provided the slides below.
LLM applications in 2025 face a unique challenge: while they enable rapid deployment compared to traditional ML systems, they also introduce new risks around reliability and safety.
In this article, I'll explain why structured outputs remain crucial for building robust LLM applications, and how they enable faster iteration and testing.
The New Development Paradigm
Traditional ML applications follow a linear path: collect data, train models, then deploy. LLM applications flip this on its head:
- Deploy quickly with base capabilities
- Collect real user data during production
- Build specialized infrastructure around the model over time
This accelerated timeline brings both opportunities and challenges. While we can get to market faster, we need robust guardrails to ensure reliability and safety.
Structured Outputs
Why Raw JSON is not enough
Many developers start by parsing raw JSON from LLM outputs, but this approach is fraught with issues:
- Inconsistent output formats and parsing errors with malformed JSON
- Difficulty handling edge cases
- Challenges with retries and validation
Function calling, supported by most major providers, solves these problems by providing structured, validated outputs. Here's a simple example using the Instructor library:
import instructor
from pydantic import BaseModel
from openai import OpenAI
class UserInfo(BaseModel):
name: str
age: int
client = instructor.from_openai(OpenAI())
user_info = client.chat.completions.create(
model="gpt-4o-mini",
response_model=UserInfo,
messages=[{"role": "user", "content": "John Doe is 30 years old."}]
)
With instructor, we get validated Pydantic objects, which are easier to work with, more reliable and much more powerful relative to a simple JSON.parse method. More importantly, we get the following benefits
- Type safety and IDE support
- Easy integration with existing codebases since we have a defined response type ( and other libraries that support Pydantic )
- Consistent interface across different providers using the same
openaiapi interface.
Beyond Simple Validation
Structured Outputs enable sophisticated capabilities like
- Class Methods : Since Pydantic objects are classes, we can define methods on them to make them more powerful.
- Field Repair : Field validators aren't just for validation, we can use them to repair fields that are the result of mispellings or other errors using deterministic logic
- Downstream Processing : Since we know the output format, it's easy to process the output in a structured way. This allows us to build more complex workflows that leverage things like streaming.
For instance, given say a set of known clothing categories, we can use libraries like fuzzywuzzy to repair mispellings in the output.
from pydantic import BaseModel, field_validator
from fuzzywuzzy import fuzz
class Product(BaseModel):
category: str
@field_validator("category")
def validate_category(cls, v: str) -> str:
known_categories = ["t-shirts", "shirts", "pants"]
matches = [(fuzz.ratio(v.lower(), cat), cat) for cat in known_categories]
best_match = max(matches, key=lambda x: x[0])
if best_match[0] > 80: # Threshold for fuzzy matching
return best_match[1]
raise ValueError(f"No matching category found for {v}")
By matching these user inputs to known taxonomies and handling spelling variations and typos, we can improve the quality of our data and make it more useful for downstream tasks. Other useful examples include defining the class methods to execute database queries once we've extracted the relevant parameters using a tool call as seen below from an article I wrote previously on going beyond vector search with RAG.
class SearchIssues(BaseModel):
"""
Use this when the user wants to get original issue information from the database
"""
query: Optional[str]
repo: str = Field(
description="the repo to search for issues in, should be in the format of 'owner/repo'"
)
async def execute(self, conn: Connection, limit: int):
if self.query:
embedding = (
OpenAI()
.embeddings.create(input=self.query, model="text-embedding-3-small")
.data[0]
.embedding
)
args = [self.repo, limit, embedding]
else:
args = [self.repo, limit]
embedding = None
sql_query = Template(
"""
SELECT *
FROM {{ table_name }}
WHERE repo_name = $1
{%- if embedding is not none %}
ORDER BY embedding <=> $3
{%- endif %}
LIMIT $2
"""
).render(table_name="github_issues", embedding=embedding)
return await conn.fetch(sql_query, *args)
Because we know the output format, building out workflows that leverage structured outputs is much easier. Here's an example of how we can stream out the result of a structured extraction query in real time as the chunks are streaming in.
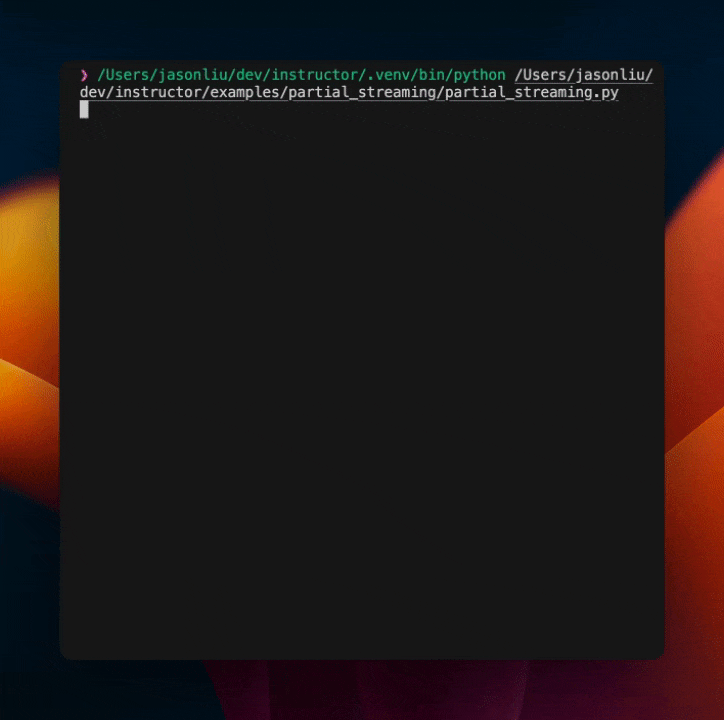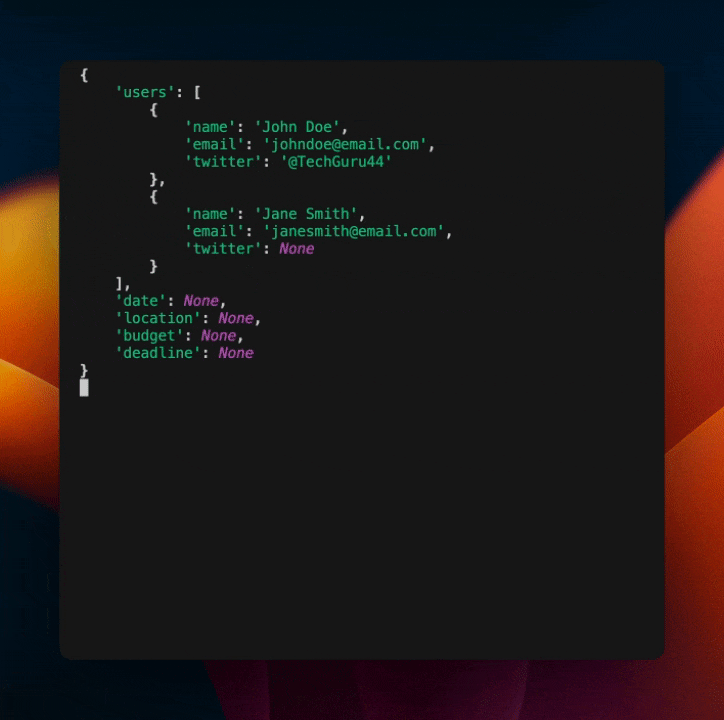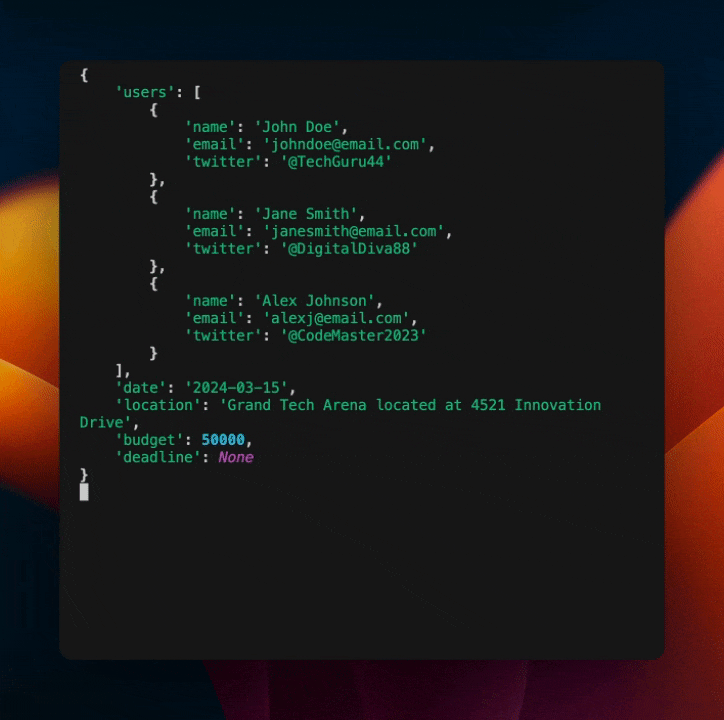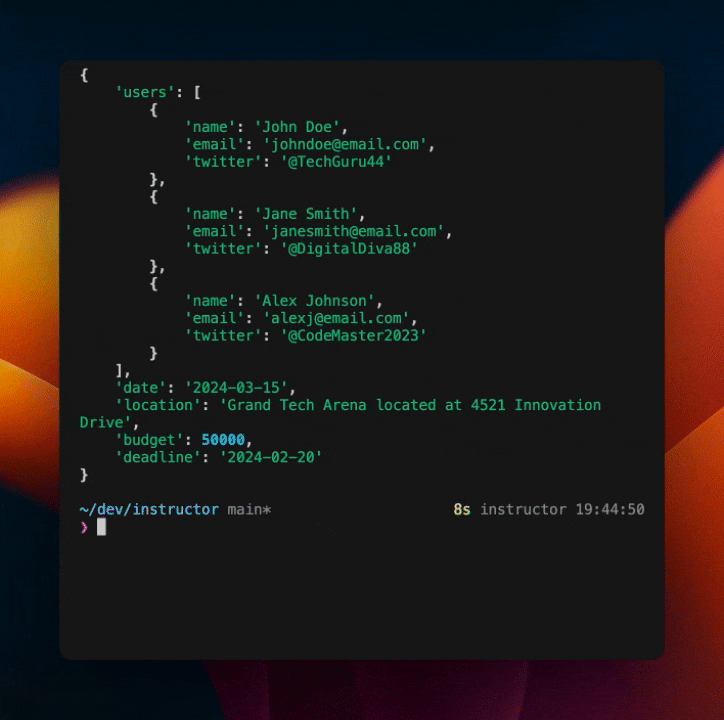
This is a simple example, but it shows how structured outputs enable more complex workflows that are not possible with raw JSON.
Prioritising Iteration Speed
Binary metrics provide a fast, reliable way to evaluate LLM system performance before investing in expensive evaluation methods. By nailing down the simplest metrics first, we can iterate quickly and make sure we're on the right track before spending our time on more complex methods that might not be as useful.
Let's look at three key areas where simple binary metrics shine:
RAG Systems
Instead of immediately jumping to complex LLM-based evaluation, start by measuring retrieval quality:
def calculate_recall_at_k(queries: List[str], relevant_docs: List[str], k: int) -> float:
hits = 0
for query, relevant in zip(queries, relevant_docs):
retrieved = retrieve_documents(query, k=k)
if relevant in retrieved:
hits += 1
return hits / len(queries)
Most importantly, we can use these queries to test different approaches to retrieval because we can just run the same queries on each of them and see which performs the best. If we were comparing say - BM25, Vector Search and Vector Search with a Re-Ranker step, we can now identify what the impact on recall, mrr and latency is.
Say we generate 100 queries and we find that we get the following results
| Method | Recall@5 | Recall@10 | Recall@15 |
|---|---|---|---|
| BM25 | 0.72 | 0.78 | 0.82 |
| Vector Search | 0.75 | 0.81 | 0.85 |
| Vector + Re-Ranker | 0.69 | 0.75 | 0.79 |
This simple metric can reveal important insights:
- If BM25's recall@15 matches vector search's recall@10, you might prefer BM25 for its simplicity
- If adding a reranker drops recall significantly, you may need to adjust your filtering
- When comparing embedding models, you can quickly see which performs better for your specific use case
Text-to-SQL
Text-to-SQL is more complex than simple query generation. Consider how experienced data analysts actually work:
- First, they identify relevant tables in the schema
- Then, they search for similar queries others have written
- Next, they consult stakeholders to understand what each field means, the hidden relationships between the fields and company-specific calculation methods
- Finally, they write the query
This process reveals why text-to-SQL is fundamentally a RAG problem. While modern LLMs can easily generate simple queries like SELECT * FROM users, real-world queries require rich context about company-specific conventions and business logic.
For example, calculating "month-over-month growth" might mean:
- Last 30 days vs previous 30 days in one company
- Calendar month comparisons in another
- Fiscal month definitions in yet another
By ensuring that we're able to obtain the right context from the database, we can now test different approaches for retrieval. This ensures that given some sort of user query, our system always has the necessary context before attempting query generation. This also means that it's easier to debug failures and progressively improve system performance in a measurable way.
Tool Selection
Tool selection in LLM applications can be evaluated using classic precision-recall metrics, providing clear quantitative insights into system performance.
- Precision measures how many of our selected tools were actually necessary
- Recall tracks whether we selected all the tools we needed.
This creates an important tension: we could achieve perfect recall by selecting every available tool, but this would tank our precision and likely create operational issues.
The balance between these metrics becomes crucial when considering real-world constraints. Unnecessary tool calls might incur API costs, add latency, or introduce potential failure points.
For instance, if a shopping assistant unnecessarily calls a weather API for every product search, it adds cost and complexity without value. By tracking precision and recall over time, we can make data-driven decisions about model selection and prompt engineering, moving beyond gut feelings to measurable improvements in tool selection accuracy.
This framework helps teams optimize for their specific needs – whether that's maximizing precision to reduce costs, or prioritizing recall to ensure critical tools aren't missed.
Query Understanding
Understanding user behavior at scale requires automated ways to analyze and categorize conversation patterns.
Kura is a library that uses language models to build hierarchical clusters of user queries, helping teams understand broad usage patterns while preserving privacy. Instead of relying on manual annotation or traditional topic modeling, Kura progressively combines similar conversations into meaningful clusters that reflect natural usage patterns.
The Value of Query Understanding
It's important to invest in query understanding early because it's vital to make data-driven decisions about product development and resource allocation. When these high level cateogires are combined with metrics like query volume and user feedback, we can
- Identify common user patterns and needs
- Prioritize feature development based on usage
- Discover emerging use cases over time
This helps us to focus on what really moves the needle - Segmentation is the name of the game here.
How Kura Works
Kura takes a hierarchical approach to clustering:
- Summarizes individual conversations into high-level user requests
- Groups similar requests into initial clusters
- Progressively combines clusters into broader categories
- Generates human-readable descriptions for each level
For example, what might start as separate clusters for "React component questions" and "Django API issues" could be combined into a higher-level "Web Development Support" category that better reflects the technical nature of these conversations.
Validating with Synthetic Data
To validate Kura's effectiveness, we tested it with synthetic data generated across multiple dimensions:
- High-level categories (e.g., technical development, content creation)
- Specific subcategories (e.g., React development, microservices)
- Varied conversation styles (different tones, lengths, user goals)
- Different conversation flows (varying turns and response patterns)
In tests with 190 synthetic conversations, Kura successfully reconstructed the original high-level categories while discovering meaningful new groupings - for instance, combining API documentation questions with software engineering queries based on their technical similarity.
Getting Started with Kura
You can try Kura at usekura.xyz or install it directly via pip using the command pip install kura.
The library offers both a simple CLI interface for quick analysis and a Python API for more complex integrations.
Whether you're looking to understand user behavior or prioritize feature development, Kura provides a systematic way to analyze conversations at scale while maintaining user privacy.
Conclusion
Building reliable LLM applications in 2025 requires a systematic approach focused on measurable outcomes. By combining structured outputs, binary metrics, and sophisticated query understanding, teams can create robust systems that improve steadily over time:
- Structured outputs through function calling and libraries like Instructor provide a foundation for reliable data handling and type safety, enabling sophisticated workflows and easier debugging
- Simple binary metrics like recall and precision offer quick feedback loops for iterating on core functionality before investing in complex evaluations
- Tools like Kura help teams understand usage patterns at scale, directing development efforts where they'll have the most impact
Most importantly, this approach transforms gut feelings into quantifiable metrics, allowing teams to make data-driven decisions about system improvements. The goal isn't to build a perfect system immediately, but to create one that can be measured, understood, and systematically enhanced over time.
As LLM applications continue to evolve, the teams that succeed will be those that combine rapid deployment with robust evaluation frameworks, ensuring their systems remain reliable and effective as they scale.
Useful Links
Here are the links that I mentioned which are compiled nicely for you to check out.
- Kura : A library for understanding user queries at scale
- CLIO : How Anthropic uses language models to understand what users are using Claude for
- RAG is more than just vector search : Why vector search is not enough for any production RAG system
- Enhancing Text-to-SQL with Synthetic Summaries : How to use synthetic data to improve text-to-SQL systems