Getting Started with Evals - a speedrun through Braintrust
For software engineers struggling with LLM application performance, simple evaluations are your secret weapon. Forget the complexity — we'll show you how to start testing your LLM in just 5 minutes using Braintrust. By the end of this article, you'll have a working example of a test harness that you can easily customise for your own use cases.
We'll be using a cleaned version of the GSM8k dataset that you can find here.
Here's what we'll cover:
- Setting up Braintrust
- Writing our first task to evaluate an LLM's response to the GSM8k with Instructor
- Simple recipes that you'll need
Why bother evaluating?
Evaluations are key to building a great application. While we want to ship fast to prpduction and put features into the hands of our users, It's important to have tests so that we know how changes in our prompts, model choices and even the response object is affecting the output that we get.
Additionally, by knowing where our model fails, we can build and invest in systems that can mitigate a lot of these issues.
Setting up a Braintrust Evaluation Suite
You'll need a braintrust account to run the remainder of the code. You can sign up here for a free account.
Let's first start by installing the dependencies we'll need.
Once we've done so, we can just go ahead and copy the following code into a file called eval.py.
What this tiny snippet of code does is that
- Task : For each individual dictionary in the
datalist, it will call thetaskfunction with theinputfield as the argument. - ExactMatch : ExactMatch compares the LLM's output to a predefined correct answer, returning a 1 or 0 for each individual example. This means that when we add it as a score, it will compare the response obtained from the
taskfunction with theexpectedfield in the dictionary and give us a score.
from braintrust import Eval
from autoevals.value import ExactMatch
def task(input):
return "Hi " + input
Eval(
"braintrust-tutorial", # Replace with your project name
data=lambda: [
{
"input": "Foo",
"expected": "Hi Foo",
},
{
"input": "Bar",
"expected": "Hello Bar",
},
], # Replace with your eval dataset
task=task, # Replace with your LLM call
scores=[ExactMatch],
)
Because the second assertion Hello Bar won't match the response we get from task, we're only going to get a score of 50% here. This is expected since our function is hardcoded to return hi <input>.
Let's run this code using python eval.py.
> python eval.py
Experiment <> is running at <>
braintrust-tutorial (data): 2it [00:00, 4583.94it/s]
braintrust-tutorial (tasks): 100%|██████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 30.93it/s]
=========================SUMMARY=========================
50.00% 'ExactMatch' score
0.00s duration
See results for <> at https://www.braintrust.dev/<>
Now that we've got this setup, let's try looking at how we can convert this to evaluate the GSM8k dataset.
Writing our first task to evaluate an LLM's response to the GSM8k
As mentioned above, we'll be using a cleaned version of the GSM8K dataset that you can find here. I processed this dataset so that it contains a nice answer field for each question. This means that each row looks something like this.
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "72",
"reasoning": "Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May."
}
What we want to do is to essentially give gpt-4o-mini the question, and then ask it to produce the answer and the reasoning that led to the answer.
To do this, we'll be using the instructor package that we installed.
from braintrust import Eval
from autoevals.value import ExactMatch
from datasets import load_dataset
import instructor
import openai
from pydantic import BaseModel
# First we take the first 10 examples from the gsm8k dataset
ds = load_dataset("567-labs/gsm8k", split="test").take(10)
client = instructor.from_openai(openai.OpenAI())
def task(question: str):
class Answer(BaseModel):
chain_of_thought: str
answer: int
return client.chat.completions.create(
model="gpt-4o-mini",
response_model=Answer,
messages=[
{
"role": "system",
"content": "You are a helpful assistant that solves math problems. You are given a question and you need to solve it. You need to provide the answer and the steps to solve the problem.",
},
{"role": "user", "content": question},
],
).answer
Eval(
"braintrust-tutorial", # Replace with your project name
data=lambda: [
{
"input": row["question"],
"expected": row["answer"],
}
for row in ds
],
task=task, # Replace with your LLM call
scores=[ExactMatch],
metadata={"dataset": "gsm8k", "split": "test", "n_examples": 10},
)
When we run this code, we should see an output that looks something like this.
> python eval.py
Experiment <> is running at <>
braintrust-tutorial (data): 10it [00:00, 17389.32it/s]
braintrust-tutorial (tasks): 100%|████████████████████████████████████████████████████████████████| 10/10 [00:11<00:00, 1.12s/it]
=========================SUMMARY=========================
---
100.00% (+100.00%) 'ExactMatch' score (10 improvements, 0 regressions)
4.29s (+12.34%) 'duration' (7 improvements, 3 regressions)
See results for <> at https://www.braintrust.dev/app/567/p/braintrust-tutorial/experiments/<>
This is a good score and our LLM is performing well. Better yet, with Braintrust, we're able to capture the entire evaluation suite from start to finish.
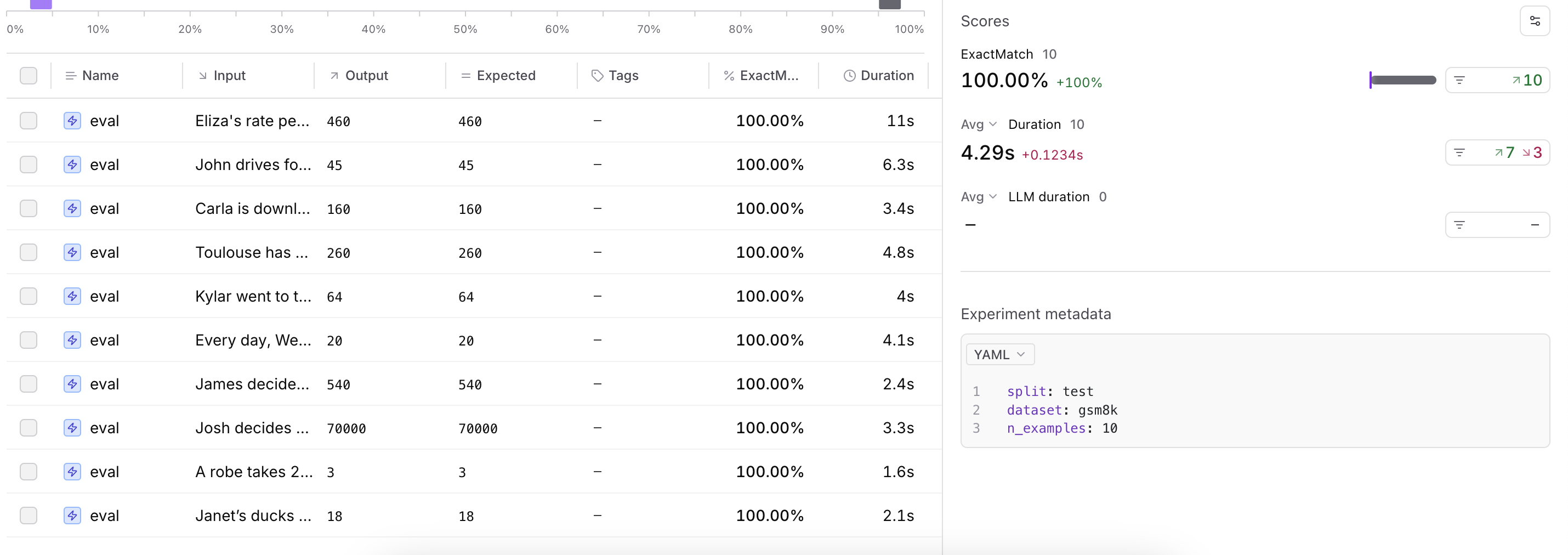
However, if we try to scale this up we're going to run into some problems. The main problem here is that we're not able to run our evaluations asynchronously and we're running each call sequentially.
Thankfully the answer isn't very complicated. All we need to do is to change our client to the AsyncOpenAI client, our task to an asynchronous function and then make a few small adjustments to the Eval function.
We can try running the code snippet below and we'll see that the code runs a lot faster.
from braintrust import Eval
from autoevals.value import ExactMatch
from datasets import load_dataset
import instructor
import openai
from pydantic import BaseModel
import asyncio
# First we take the first 10 examples from the gsm8k dataset
ds = load_dataset("567-labs/gsm8k", split="test").take(30)
client = instructor.from_openai(openai.AsyncOpenAI())
async def task(question: str):
class Answer(BaseModel):
chain_of_thought: str
answer: int
return (
await client.chat.completions.create(
model="gpt-4o-mini",
response_model=Answer,
messages=[
{
"role": "system",
"content": "You are a helpful assistant that solves math problems. You are given a question and you need to solve it. You need to provide the answer and the steps to solve the problem.",
},
{"role": "user", "content": question},
],
)
).answer
async def main():
await Eval(
"braintrust-tutorial",
data=lambda: [
{
"input": row["question"],
"expected": row["answer"],
}
for row in ds
],
task=task,
scores=[ExactMatch],
metadata={"dataset": "gsm8k", "split": "test", "n_examples": 30},
)
if __name__ == "__main__":
asyncio.run(main())
We can see that the code works just as well, but it runs a lot faster. Better yet, we're able to also capture all of the generated results in the UI as seen below.
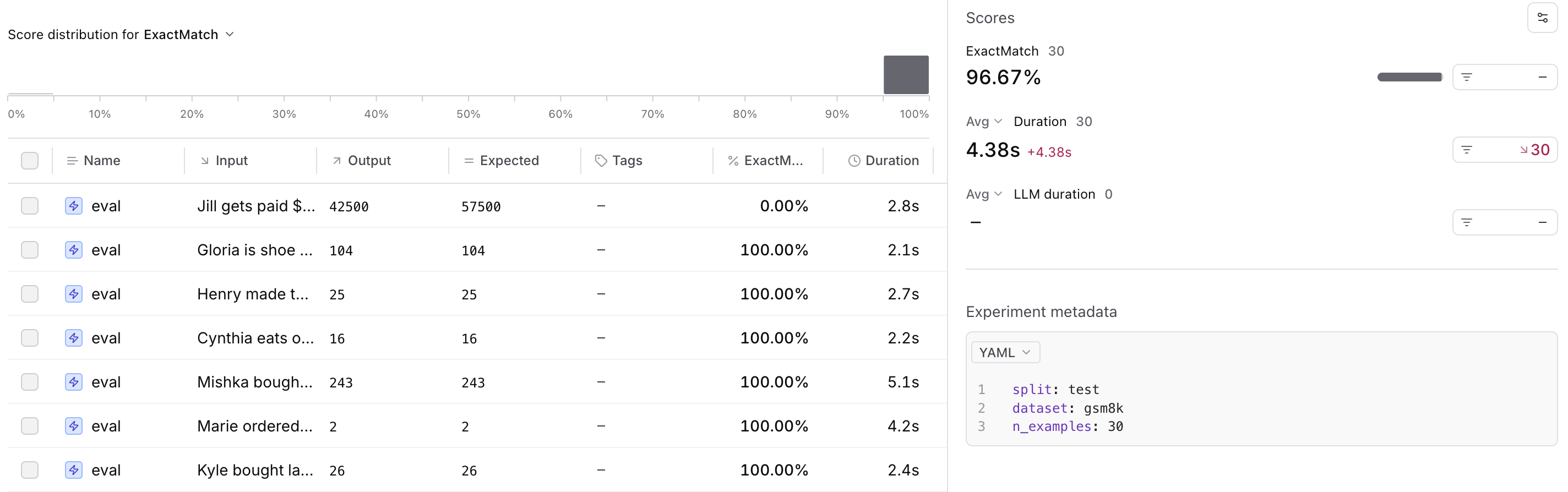
Quick Tips
Lastly, I'll leave you with a few quick tips to help make better use of Braintrust.
- Use the hooks method in Braintrust to log arbitrary information. I've found this to be very useful when you go back and try to understand why a certain model performed better than another. Better yet, having the data captured as is, helps significantly with debugging and finding difficult/challenging edge cases.
async def task(question: str, hooks):
class Answer(BaseModel):
chain_of_thought: str
answer: int
messages = [
{
"role": "system",
"content": "You are a helpful assistant that solves math problems. You are given a question and you need to solve it. You need to provide the answer and the steps to solve the problem.",
},
{"role": "user", "content": question},
]
resp = await client.chat.completions.create(
model=model,
response_model=Answer,
messages=messages,
)
hooks.meta(response_object=resp.model_dump_json(indent=2), messages=messages)
return resp.answer
- Try to parameterize different aspects of your evaluation and log as much as you can. Here's an example where we parameterize the model that we eventually end up using in tasks so that we can log it in the experiment metadata.
model = "gpt-4o-mini"
# Task code goes here
async def main():
await Eval(
"braintrust-tutorial",
data=lambda: [
{
"input": row["question"],
"expected": row["answer"],
}
for row in ds
],
task=task,
scores=[ExactMatch],
metadata={
"dataset": "gsm8k",
"split": "test",
"n_examples": 30,
"model": model,
},
)
- Write custom scorer functions - these are useful in helping to capture functionality that isn't available in the autoevals library. The following example shows how we can calculate MRR and Recall at different values of
kin Braintrust. This is extremely useful when we want to parameterize our evaluation to run different metrics or different sizes of metrics.
def calculate_mrr(predictions: list[str], gt: list[str]):
mrr = 0
for label in gt:
if label in predictions:
mrr = max(mrr, 1 / (predictions.index(label) + 1))
return mrr
def get_recall(predictions: list[str], gt: list[str]):
return len([label for label in gt if label in predictions]) / len(gt)
eval_metrics = [["mrr", calculate_mrr], ["recall", get_recall]]
sizes = [3, 5, 10, 15, 25]
metrics = {
f"{metric_name}@{size}": lambda predictions, gt, m=metric_fn, s=size: (
lambda p, g: m(p[:s], g)
)(predictions, gt)
for (metric_name, metric_fn), size in itertools.product(eval_metrics, sizes)
}
def evaluate_braintrust(input, output, **kwargs):
return [
Score(
name=metric,
score=score_fn(output, kwargs["expected"]),
metadata={"query": input, "result": output, **kwargs["metadata"]},
)
for metric, score_fn in metrics.items()
]
We can see here that with this method, we're able to log all of our custom metrics. In Braintrust, we'll need to make sure that our scores all lie within the Score class so that we can capture them properly. We can then call this function using the high level Eval function as seen below.
Eval(
"MS Marco", # Replace with your project name
data=lambda: [
{
"input": query,
"expected": label,
"metadata": {"search_type": "fts", "k": "25"},
}
for query, label in zip(queries, labels)
], # Replace with your eval dataset
task=lambda query: [
row["chunk"]
for row in table.search(query, query_type="fts")
.select(["chunk"])
.limit(25)
.to_list()
],
scores=[evaluate_braintrust],
trial_count=3,
)
- Use the
taskmethod as a way to run calls, this is great when your evaluation logic requires more than just theinputparameter.
def task_scoring_function(input, arg1, arg2, arg3):
return compute_something(input, arg1, arg2, arg3)
def task(input):
return task_scoring_function(input, arg1, arg2, arg3)
await Eval(
...
task=task, # This is an easy way if we have a bunch of different parameterized tests that we'd like to
)
- When running a set of Evals, make sure to save the resulting
Resultobject that's returned to you. This is extremely useful when you want to see all of the results in a single place.
result = Eval(
"MS Marco", # Replace with your project name
data=lambda: [
{
"input": query,
"expected": label,
"metadata": {"search_type": "fts", "k": "25"},
}
for query, label in zip(queries, labels)
], # Replace with your eval dataset
task=lambda query: [
row["chunk"]
for row in table.search(query, query_type="fts")
.select(["chunk"])
.limit(25)
.to_list()
],
scores=[evaluate_braintrust],
trial_count=3,
)
# This can be saved into an array for you to print out at the end of your script
experiment_name = result.summary.experiment_name
experiment_url = result.summary.experiment_url
scores = result.summary.scores
summarized_scores = [f"{result.summary.scores[score].score:.2f}" for score in scores]
I hope this helped significantly with getting started with Braintrust. If you have any questions, please feel free to reach out to me on twitter @ivanleomk. I struggled a fair bit when I was getting used to it so hopefully this helps!