I've spent the last year working with LLMs and writing a good amount of technical content on how to use them effectively, mostly with the help of structured parsing using a framework like Instructor. Most of what I know now is self-taught and this is the guide that I wish I had when starting out.
It should take about 10-15 minutes at most to read and I've added some resources along the way that are relevant to you. If you're looking for a higher level, i suggest skimming over the first two sections and then focusing more on the application/data side of things!
I hope that after reading this essay, you walk away with an enthusiasm that these models are going to change so much things that we know today. We have models with reasoning abilities and knowledge capacities that dwarf many humans today in tasks such as Mathetical Reasoning, QnA and more.
Please feel free to reach on twitter at @ivanleomk if you're interested to chat more!
Some Background
Quick Definitions
I'll be using some words here so I'll try to define it
- Features: A number that represents something (eg. the number of legs on a car for example)
- Sequence : A list of numbers or a list of list of numbers. This is what we feed into our model
- Model : A series of operations that we specify using numbers that we learn through training
Deep Learning
Machine Learning models are hard to train. Traditionally, we've had to rely heavily on curated datasets and architectures for every single task or get experts to curate specific features for each task.
In the past 20 years, we got really fast computers and chips that allowed us to train much larger models. This was key because the way we train these models is by
- Taking some input (normally a list of numbers)
- Running it through our model ( getting out a list of numbers )
- Keeping track of all the operations that got us to the final result using a giant graph we call a computational graph
- Using an algorithm called back propogation to calculate how we should update the numbers in our model to get better results
Intuitively as our models grow larger ( have more numbers and operations to multiply inside to get a final result ), the amount of data that we need to train them AND the amount of operations to calculate to update the weights increases significantly. The complexity also increases significantly.
But, these networks weren't able to deal with/represent inputs that require more complex reasoning since they take a single input and produce a single output.
RNNs and LSTMs
A good example of such tasks are machine translation
which can be roughly translated to
We can't do an exact translation on a word level for many of these sentences. That's when we started using things like RNNs. I'm going to gloss over the exact specifics of how they work but on a high level, it works like this
def rnn(input):
hidden_state = [0]*len(hidden_state) # Using 0 here cause it's easy but it could very well be a nested array of arrays!
for token in input:
output,hidden_state = model(input,hidden_state)
return output
At each step, we produce two outputs, a hidden state and a output vector. These don't need to be of the same dimensions ( containing the same number of vectors ) and often times, the hidden state will be larger than the output vector.
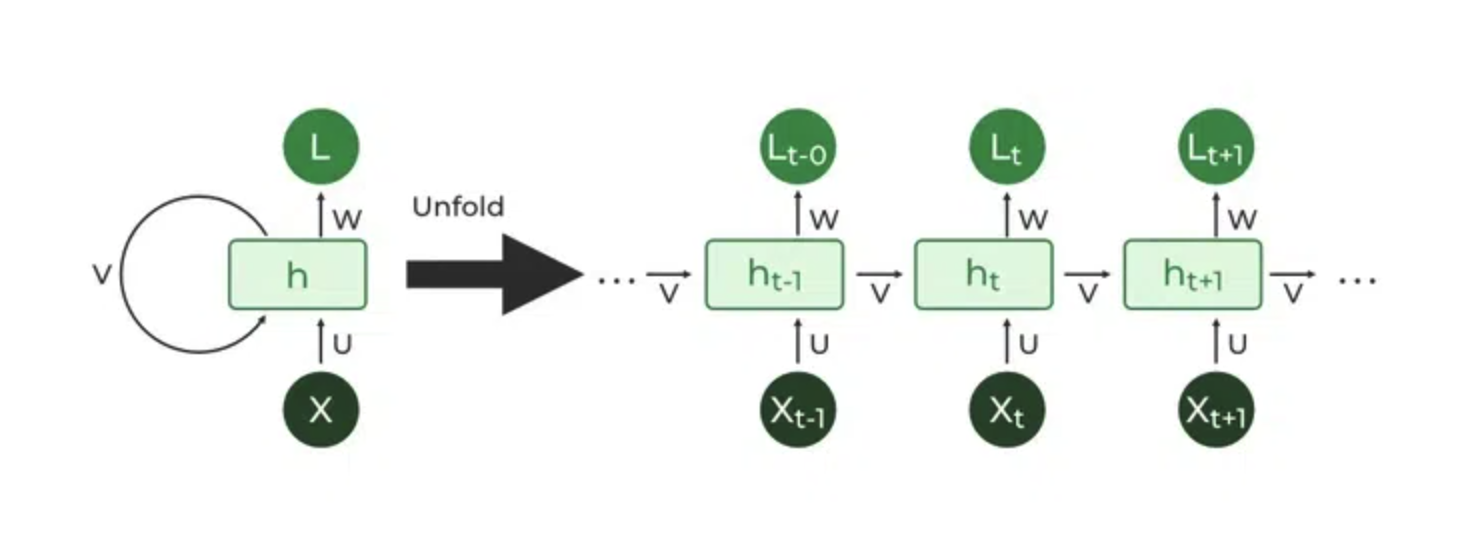
But this was great! Because we now have a way to map a sequence of tokens to another sequence of tokens. This is super flexible and allows us to map from
- a sequence of pixels from an image to a sequence of text chunks
- Sentiment analysis
Eventually some people realised that we could also just use 2 RNNS - one would encode the input into some hidden state and the other would decode it into an output that we want.
def rnn(input):
hidden_state = [0]*len(hidden_state) # Using 0 here cause it's easy but it could very well be a nested array of arrays!
for token in input:
output,hidden_state = model(input,hidden_state)
return output,hidden_state
# Note these will be two RNNs with separate and different weights
_,hs = rnn(sentence)
o,_ = rnn(hs)
This worked pretty well for machine translation for some time but RNNs had a major problem.
- They process one chunk of input at a time and so it's difficult to deal with long sequences when something near the end of the sequence
- When we reach the end and finally see whether our prediction matches the result we want, it is dificult to update/make changes to the weight with respect to the first few chunks of inputs.
- It's difficult to parallelize the processing of multiple chunks - since we need to feed in one token at a time there's no way to skip from the first token to the 100th in a single step. This makes training RNNs on large sequences very difficult since it'll take a long time to do so.
People proposed LSTMs and GRUs ( Which are RNNs that are slightly modified ) to solve this but these didn't achieve the desired result that we wanted.
Attention
To do a quick recap, RNNs store their hidden state in a single vector as they process more bits of input. However, this means that some information is lost down the line, especially as we might encounter input tokens that make prior tokens relevant again.
Therefore a simple solution emerged, why not we store all of the prior hidden states in memory and allow our model to learn how to combine/weight them?
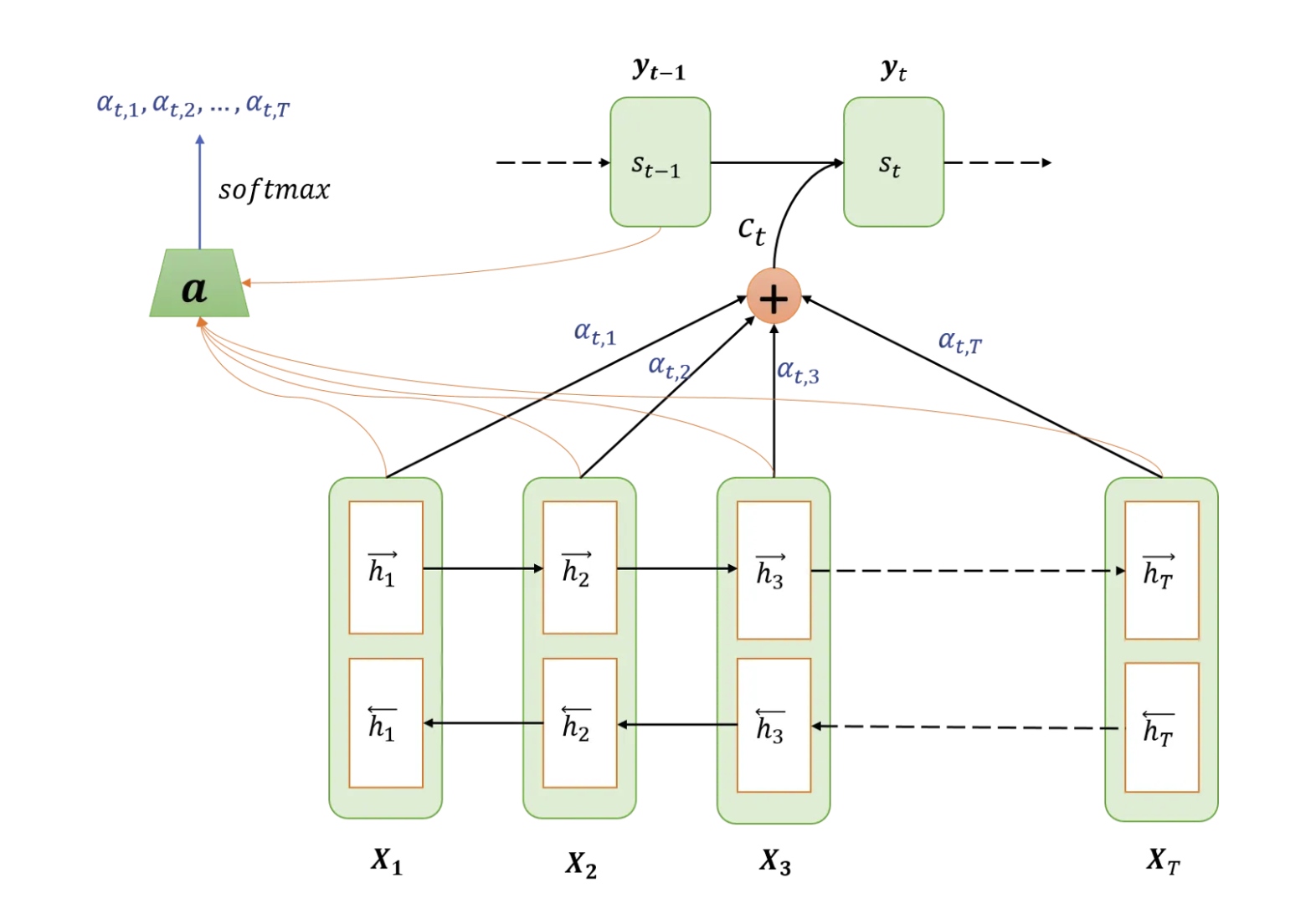
This helped to achieve some good results and greatly improved experimental outcomes. Notably, these hidden states encoded some degree of position because they were incrementally derived from each other, which is something transformer attention needed some tweaks to do.
Transformers
Transformers were proposed as an alternative to these networks with the key idea that instead of processing one input token at a time, we should evaluate the entire sequence at the same time. They incorporated this idea of attention into the architecture of the model and proposed a new variant of attention they called Scaled Dot Product attention. We'll go through a high level overview of what Attention looks like in a transformer in a bit.
If there's anything that I think you should take away from this section, it's that Transformers are more than stochastic parrots that are randomly predicting the next token. At each step they have ~50,000 different choices ( depending on the tokenizer). To achieve good performance on this task, they must learn important inforamtion about the world from the data.
We can think of them as compressing information into the finite storage that they have. Storage here refers to the number of parameters that they have. Larger models perform better because they can store more information but ultimately how much and how good the data they manage to see during training determines their performance to some degree.
They're exciting developments because we can prompt them to do tasks we want. We can fine-tune them on specific datasets to get a specific type of outputs but the fact that we can say stuff like no yapping and have it immediately produce shorter responses is nothing short of pure magic.
How they work
Your transformer model never sees text directly, instead it just sees tokens.
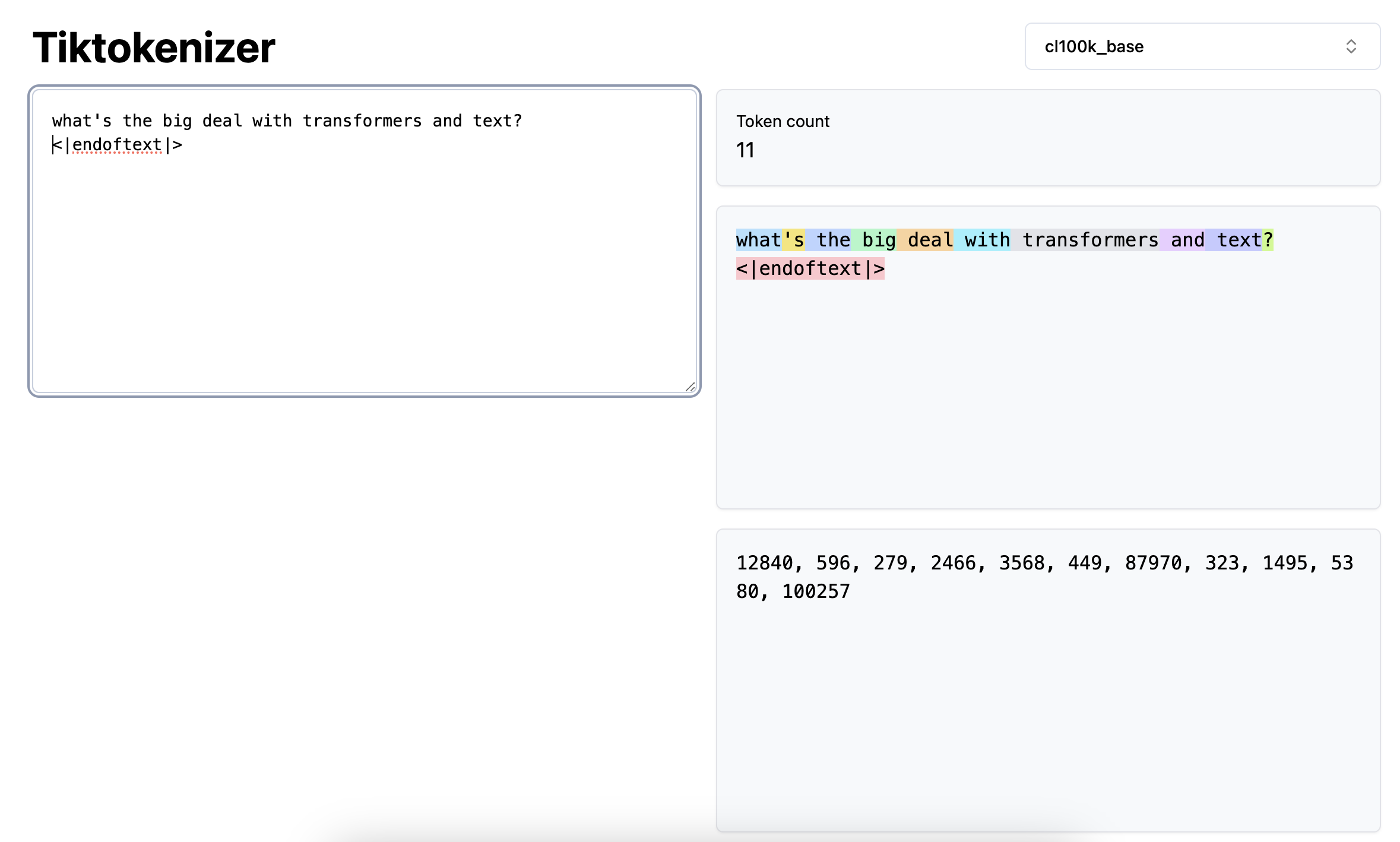
We use algorithms such as Byte Pair Encoding and sentence piece and run them on a large corpus of text to choose a selection of tokens that we can use to break down text. The less tokens we can use to represent a specific prompt, the cheaper it is for inference.
It might also mean that we get better performance.
This also means that languages that are not well represented online typically aren't able to be compressed well and need more tokens
On a high level, this is how it works with your transformer
![]()
On a high level, this is how inference might work with a transformer
![]()
It has a known mapping of tokens ( think subwords eg. The, France) and each token has a unique id. It then converts the text you pass in to the token ids and outputs a new vector.
This vector has the same size as the mapping it has and corresponds to the probability of a token being the next token in the sequence.
That's why transformers are often known as auto regressive generative models, because they generate predictions for these tokens AND because future generated output are conditioned on prior output tokens that were chosen to be used.
Attention in Transformers
This is a tricky topic and took me some time to understand. I recommend looking at GPT in 60 Lines of Numpy and The Illustrated GPT-2 which cover this in much greater detail. This is how attention works specifically for decoder-only transformers.
Remember how we had the RNN combine different previous hidden states for each individual token? Well, in this case, the magic happens through the following process when we feed our transformer some text.
Positional Embeddings
First, we break the text down into tokens using a tokenizer.
Next, each token gets mapped to a real number vector, This is known as an embedding. Note that this is a vector that is learnt during training and is unique for each token. It's supposed to encode some semantic meaning about the token itself. I made up some embeddings here
sample embeddings => {
2127: [1,2,3,4],
7671: [2,2,2,3],
47282: [3,1,2,5],
73423: [8,4,3,2]
}
[2127, 7671, 47282, 73423]
=> [
[1,2,3,4],
[2,2,2,3],
[3,1,2,5],
[8,4,3,2]
]
Notice here that our token would have the same vector irregardless of position. If it was Shake an Avacado vs an Avacado Shake, the Shake here refer to two very different things even if it's the same word.
Therefore, we add what's called a positional encoding. This is just a value that we compute for each number in each vector. It's the same regardless of the token, and only depends on the position of the token. More importantly, the model uses this value with a lot of training to be able to understand the position of the token.
[
[1,2,3,4] + [1,2,3,4]
[2,2,2,3] + [5,6,7,8]
[3,1,2,5] + [9,10,11,12]
[8,4,3,2] + [13,14,15,16]
]
=>
[
[2, 4, 6, 8]
[7, 8, 9, 11]
[12, 11, 13, 17]
[21, 18, 18, 18]
]
Attention Mechanism
Before we go into how it works, I want to point out why attention is needed. For a text model, we want our model to be able to generate some understanding of a specific token in relation to the sentence/input.
This is important because our model is trained to predict the next token in a sequence. Without a strong understanding of the underlying meaning of each token in the sequence, it's not going to be able to do a good job.
Therefore, we use attention as a way to do two things
- Create a representation for each individual token
- Generate a weightage for each token and every token prior to it - we don't want tokens to get information on any of the future tokens after it. That'll be cheating after all
Once we have this, we basically have a new representation for each token that is a weighted sum of all the relevant tokens prior to it. More importantly, there were two big improvements for transformers as compared to RNNs
- The entire input sequence could be trained in parallel since we're just doing basic matrix multiplication. Compare this to an RNN which processes each input token incrementally. This meant that we could scale our datasets to much larger sizes, allow our model to learn better representations of data and in turn make better predictions.
- By splitting up the generated representation using multi-head attention, we can allow our model to learn to process different semantic meaning in each subset of the vector. This means that we could extract much richer representations.
This is on a high level how attention works
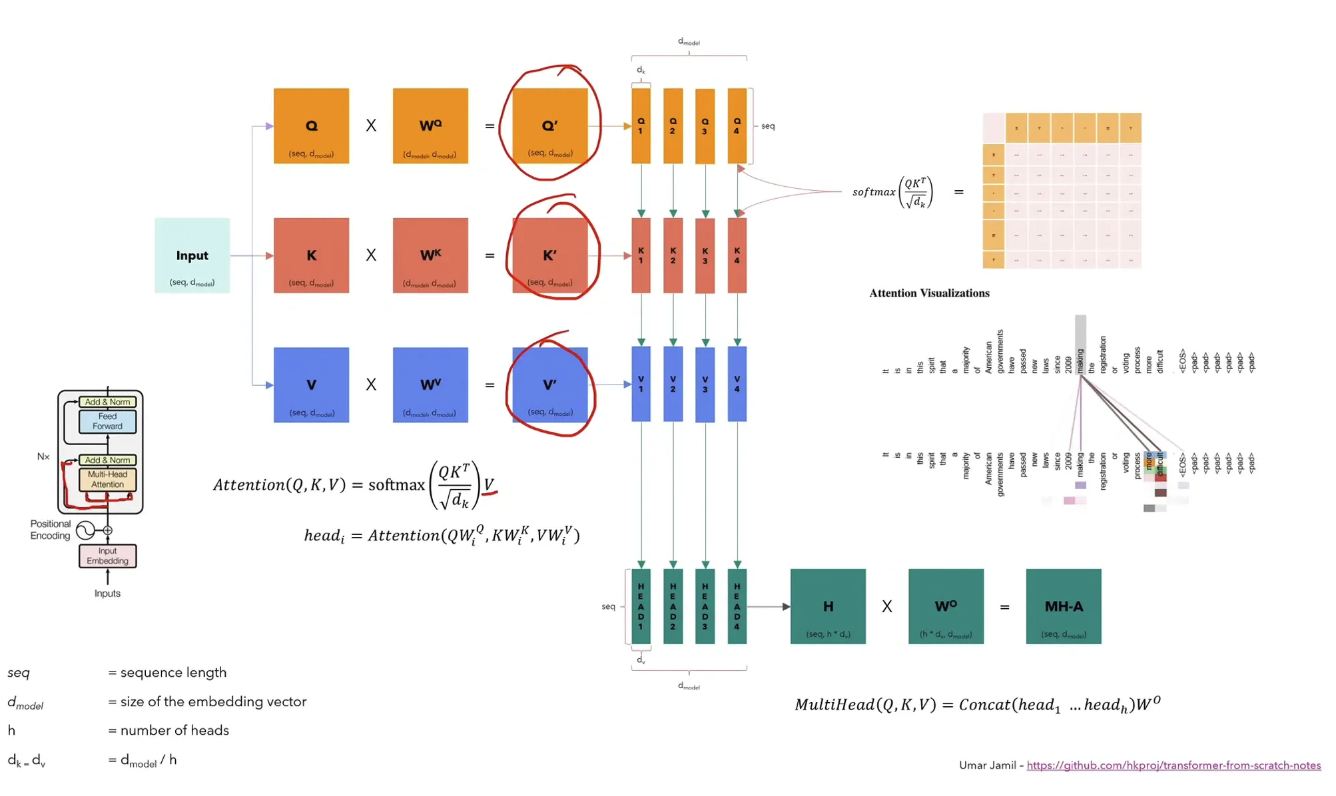
We basically take our input representation and multiply it with three separate matrices and get back three new matrices. These are known as the Query, Key and Value Matrix. It's easiest to think about them as
- Query : What each token is looking for
- Key : What each token can offer to other tokens
- Value : Some semantic meaning
We multiply our generated Query and Key matrix together and get a weightage for each token at each position. Taking our earlier tokens for example, we might get something like what we see below when we multiply our query and key matrix together.
Next, we perform a matrix multiplication of this matrix with the value matrix. This operation aggregates the values for each token across each row, weighted according to the defined percentages in each row. Once we've done so, we feed it through a normal linear network that further enriches this vector of numbers.
The way I like to think about it is that the attention operation combines semantic meaning of different tokens at each position while the linear layer helps us to make sense of this new information. We then do this multiple times and the final result helps generate the prediction.
Training a Model
So, how are transformers usually trained? Today, the process is complicated with newer models using different methods such as DPO, KTO but we're going to just look at RLHF today. I'll be borrowing some graphics and content from Chip Huyen's article on RLHF. For a more in-depth look, do refer to that article.
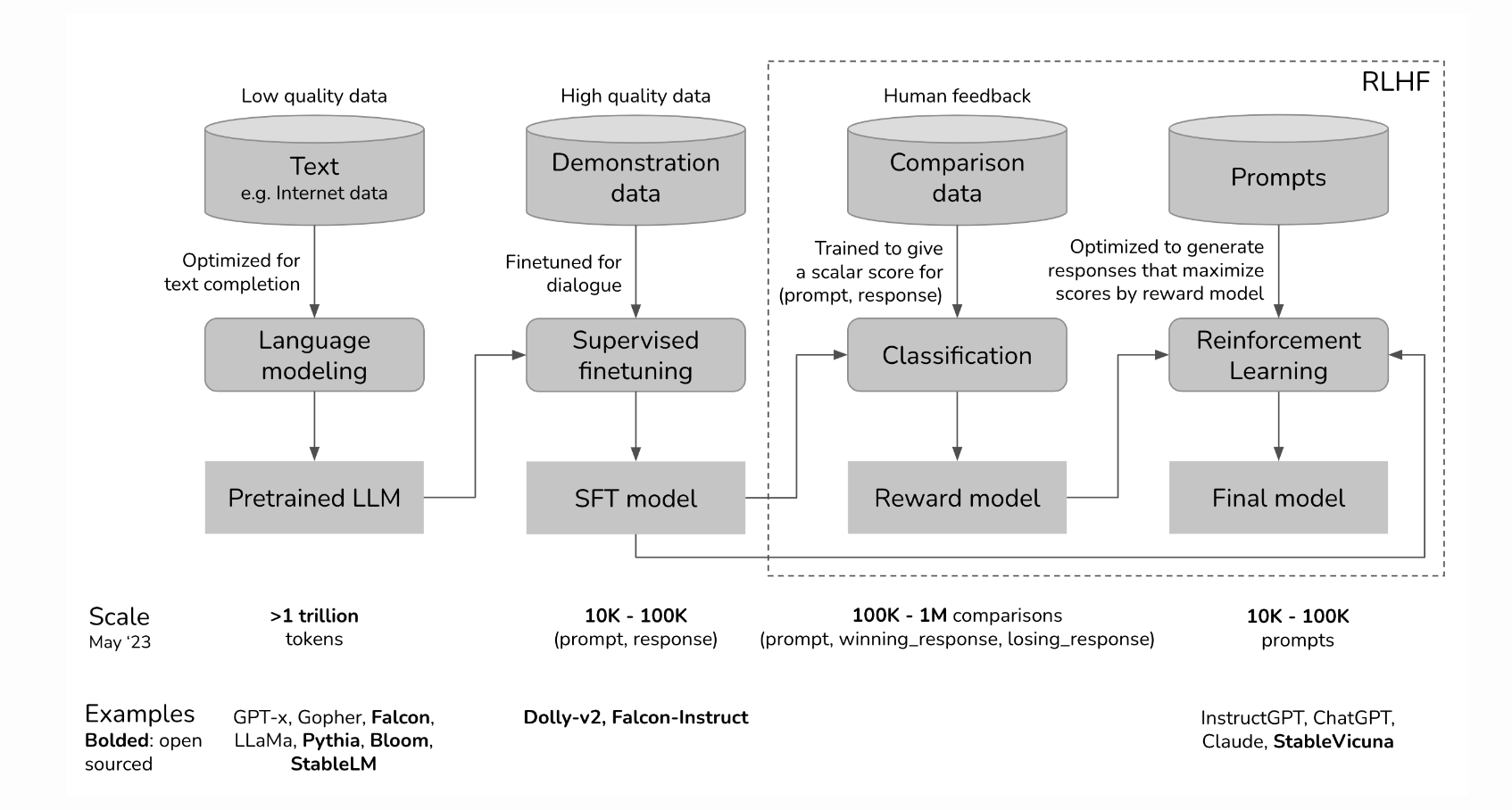
We'll cover this in three parts
- How to train a base model
- How to get the same base model to understand a prompt template and get a SFT model
- How to make sure the SFT model outputs good responses
Just to re-iterate. The big plus here now is that instead of fine-tuning on a specific dataset for one-task. These models were trained so that we can get pretty good performance... just by writing a nice paragraph/prompt. This was mindblowing back in the day, even in GPT-2 where they achieved state of the art performance for many benchmarks with a simple written instruction.
In short, instead of fine-tuning on the task, these models were fine-tuned to understand and follow instructions which allowed them to take advantage of the information/capabilities that they had learnt during pre-training.
Pre-Training
Well, how do we make sure that our transformer knows enough so that it outputs a good probability distribution? That's where the pretraining stage comes in.
If we have a lot of text (eg.)
We can split this into many training examples by taking a slice of text and trying to make the model predict the next completion from its known vocabulary.
The Capital of France is ---> Paris
Capital of France is Paris ----> It's
of France is Paris It's ----> a
This is a semi-supervised approach because the training examples used aren't generated by human annotators but instead come naturally from the text itself. The important thing to note here is that our model has to learn an awful lot of information in order to predict the next token accurately,
For example
This requires the model to be able to
- Have a concept of time and what 2008 was
- Know what a president is
- Look through its known list of presidents
- Identify who was the president was at that point of time
Once we train the model with enough data, this becomes what is known as a Base Model. Base models are great but they can't follow instructions.
That leads us to the next step - Structured Fine Tuning.
SFT ( Structured Fine Tuning )
Base Models are unable to follow instructions. They might have the knowledge and capability to answer the question but aren't trained to do so. We can see this in an example below from the InstructGPT paper.

We can see that the Base GPT-3 model simply returns a completion. It seems like it might have seen this question inside its training data itself. However, the InstructGPT model ( despite having 100x fewer parameters ) was able to understand the exact instruction and return a valid response.
Fundamentally, this just means getting the model itself to learn a specific format of instructions. Here's another example taken from the InstructGPT paper. The [Completion] portion simply indicates where the model was left to generate the text free flow.

Nowdays, these formats have evolved to more complex versions. I've found an example of the OpenAI Chatml format which is frequently found.
<|im_start|>system
You are InternLM2-Chat, a harmless AI assistant<|im_end|>
<|im_start|>user
Hello<|im_end|>
<|im_start|>assistant
Hello, I am InternLM2-Chat, how can I assist you?<|im_end|>
Instead of just merely being an instruction -> response pair, we now have various different roles avaliable, including system roles that might include information that we don't want the user to see.
RLHF
Now that our model has learnt how to generate valid responses to user prompts, we need to make sure that they're good responses.
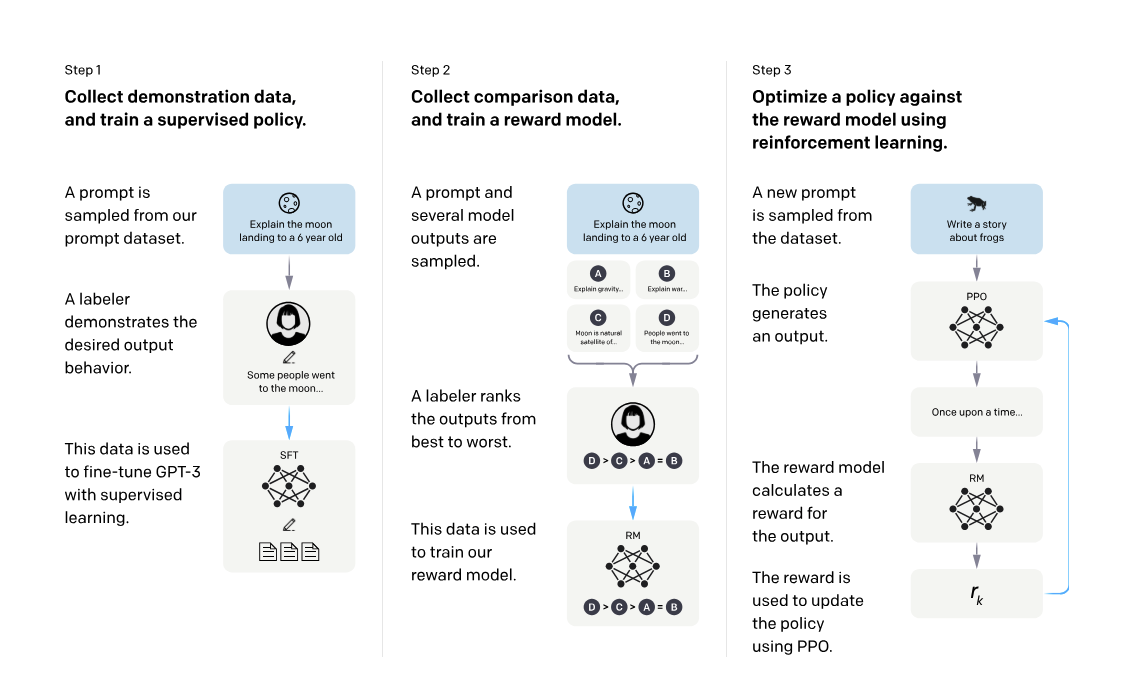
The key idea here is that we take a new model ( this could be the same model itself, just with the vocabulary vector modified to produce a single output instead using a linear layer ) and train it to output a single score given a prompt.

We're using a log sigmoid function here. So that means that the greater the positive difference between the two generated values, the smaller the loss.
There's a key reason why we do so - it's much easier for us to get labellers to compare answers than to write new prompts from scratch. Therefore, we can generate a much larger dataset for the same cost.
Since it's easy to get our language model to generate prompts, all we then need to do is make sure that the reward model eventually learns to rank responses similarly to the labellers themselves.
Current Work
InstructGPT was released almost 2 years ago in Mar 2022. What's changed since then?
- Model sizes have only grown larger
- We're still using the transformer architecture ( though some models introduce some different operations or switch the ordering of some operations )
- People have started experimenting with many different forms of fine-tuning - Some notable exampes are DPO which directly uses the probabilities of the tokens, LLama 2 using two separate reward models for Harmfulness and Helpfulness and even methods like SPIN that take advantage of synthetic data
Data Wars
So, now that we know what transformers are and why we should care, let's try and understand why people have been talking about running out of tokens.
Here's a useful podcast from latent space about dataset and tokens and an article on tokenization cost for low resource languages
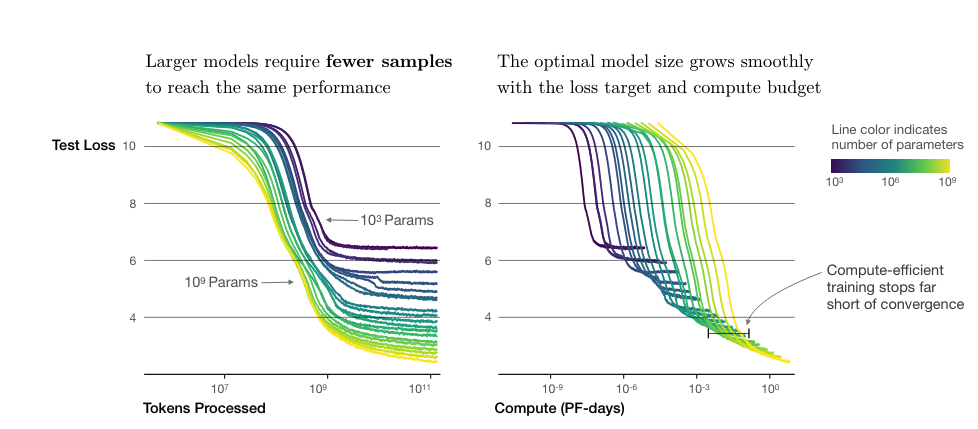
In short, these models scale proportionaly to the amount of tokens they see and the amount of parameters they have. The more parameters they have, the more capacity they have for reasoning and learning. But, that also means that we need significantly more tokens to train these parameters to the right amount. ( See this paper which describes how to train models with limited data for low resource languages.)
The important here is that quality and quantity of tokens is a challenging issue. We want high quality tokens ( Good examples of natural language / sentences ) but also sufficient quantity of tokens so that our model can learn something useful. Important to also note that copyright has become a huge issue in light of this.
Let's look at the LLama models for context to see how they've changed over time
- Llama 1 : ~ 1 Trillion tokens
- LLama 2 : 2 Trillion Tokens
- Llama 3 : 15 Trillion tokens
Interestingly, there've been a lot of new efforts to increase the usage of synthetic data in transformers.
Notable efforts include a paper by Apple which used a synthetic dataset based off paraphrased content, using a language models to generate synthethic data to further train itself and more.
to be clear, there's a huge amount of information out there, GPT-3 was trained on less than 1% of the internet. What matters is whether we're able to get access to the data and if it makes a difference.
Using LLMs
Now that we understand what LLMs are and why we care about them, let's look at some common usecases.
There are a few different use-cases that will keep popping up
- Agents
- Workflows
- RAG
Let's walk through them and roughly understand what the challenges are. It's important here to re-iterate that LLMs are difficult to work with because of ther non-deterministic nature.
Workflows
An easy fit for LLMs therefore are simple tasks.
By prompting the model to perform a specific task, we can use LLMs to easily work with data in different forms. They're very good at understanding text because of how much text they've seen. But, this often means that we might get back nonsense or text in the wrong format.
Prompt: Here's an email : <email>. Please classify as spam or not spam.
Bad Response: SPAM
Bad Response: Thank you for the great question! I think that this is probably a spam email
It's helpful to slap on some validation on the results. I like using Instructor which provides an easy way to work with structured outputs with your favourite llm provider.
If you choose to go down the workflow route, you should in turn be thinking a bit about
- How can I capture my outputs? - eg Logfire
- Can I add in specific validation to my outputs? - eg Pydantic + a second call to another model to validate the output of the first
- Can I off-load specific portions of a task to other models / start fine-tuning - eg. We generate a lot of data using an LLM. Can we train a BERT model to replace parts of it?
In short, you want to start with expensive models that don't need that much hand holding, get a lot of training data from users then progressively move on to smaller models optimised for one specific section of the task. User data will always be better than any synthetic data you can generate.
But, We can do so much more than this! By getting models to output a response in a specific format, we can hook up our models to real-world systems that enable it to perform actions such as send an email, execute terminal commands or even search the web! See Gorilla for an example of a model that is tuned to do so.
RAG
RAG is short for retrieval augmented generation. Remember how I mentioned earlier that models are essentially building a world model. This means that they have a fixed state of the world and will not be able to answer questions about specific domains (Eg. your company insurance policies ) or facts that happened that weren't included in their training data (Eg. recent news/events )
So, a common use-case is to inject this information into the prompt itself so the model knows what you care about.
<|im_start|>system
You are InternLM2-Chat, a harmless AI assistant<|im_end|>
<|im_start|>assistant
Here is some relevant information on the user's query
- The latest product offering is our Penguin C2
- The C2 is retailing for 200 bucks
Make sure to only state what you know<|im_end|>
By injecting this information into the prompt, the model is able to get access to up to date information, and thus generate better responses. While initially, we can find relevant chunks using embeddings, whole systems will need to be built around these chatbots to reliably/accurately extract and find the right chunks to inject into the prompt on demand. This is a huge and complex decision.
See Rag Is More Than Embedding Search for a better overview.
Agents
Now, we've covered how to get LLMs to perform specific tasks and get up to date information that wasn't in their training data. So, what happens if we let transformers run wild? Well, that's the idea of an agent.
Basically we get the model to keep running until some abstract objective is reached (Eg. Build me a todo list) and that often takes a long time. A cool example of an agent is Devin, a LLM that has been fine-tuned and trained to create/contribute to massive code-bases on its own.
Agents became popularized through libraries such as AutoGPT where people used to give a starting prompt and then let the model run wild for many many hours. This was an extension of a prompting framework called ReACT which gets the model to generate reasoning before deciding on an action.
An example is seen below.
Question: What is the elevation range for the area that the eastern sector of the
Colorado orogeny extends into?
Thought 1 : I need to search Colorado orogeny, find the area that the eastern sector
of the Colorado orogeny extends into, then find the elevation range of the
area.
Action 1 : Search[Colorado orogeny]
Observation 1 : The Colorado orogeny was an episode of mountain building (an orogeny) in
Colorado and surrounding areas.
... continue execution
Langchain also has a similar concept called Chains - allowing users to define specific ReACT agents and chaining these calls together.
What's next?
Now that we've got a good understanding of roughly some of the latest trends, here are some of the interesting problems that I forsee moving forward.
- Evals - Large language models generate free form text. How can we ensure that we're generating input that is valid ? - see Shreya Shankar on Vibe Checks and Pydantic is all you need by Jason Liu
- Optimizations - as Transformers grow in size and we want to support greater context length, how can we build our models so that they're able to scale well? - See Mixture of Experts , Mixture of Depths, Ring Attention
- Transformer Alternatives - Is it time to go back to RNNs with alternatives such as RWKV and Mamba and Jamba?
This is a massively evolving field but I hope this was a good first step and introduction.