You're probably not doing experiments right
I recently started working as a research engineer and it's been a significant mindset shift in how I approach my work. it's tricky to run experiments with LLMs efficiently and accurately and after months of trial and error, I've found that there are three key factors that make the biggest difference
- Being clear about what you're varying
- Investing time to build out some infrastructure
- Doing some simple sensitivity analysis
Let's see how each of these can make a difference in your experimental workflow.
Knowing what to vary
It's important to think a bit upfront about what you're varying. If you're not sure, you might probably want to try prompting O1 for a fair bit.
Let's take prompt engineering for instance.
A common mistake I see is jumping straight to a complex prompt, adding in chain of thought reasoning, few shot examples and then complex validation steps. This is great but often times, it's probably best to start with something simpler and gradually add complexity.
This helps save on your token costs but more importantly, it helps you to understand what additions actually improve your results and which ones are overhead. By starting with a strong baseline, and then systematically varying specific parts of the prompt and adding complexity, you can figure out what's actually helping your model.
Fast Feedback Loops
Fast feedback loops are extremely under-rated when it comes to running experiments. Often times, they're the difference between some great results and a lot of frustration.
Typically your experiment will fall into one of two categories
- A binary benchmark evaluation - Eg. Recall, MRR , Accuracy. In this case, you want to make sure that it's as easy for you to get your results
- A more subjective form of evaluation
Let's see how we can speed up each of these.
Benchmark Evaluation
There are really two big things you want to have when doing simple binary metrics
- Good logging Infrastructure
- Easy ways to vary your components
When looking at binary metrics, it's important to invest in comprehensive logging infrastructure. I like braintrust because it provides an easy interface via the Eval class and allows you to track everything using arbitrary dictionaries ( even within the task itself that you're executing ). Often times, I've found that I've had to go back and look at the old runs with the data I saved in order to answer a question I had thereafter.
Recently, I was doing a small experiment to test whether adding long and short prefixes to SQL snippets before re-ranking improve Recall and MRR. I had two real options - one was to create separate collections and then run the same prompt on both. The other was to modify the ranker method to accept transformation functions.
With lancedb, that wasn't too difficult because all I had to do was to override an underlying _rerank method and force it to apply the modified prefix before re-ranking. But that made it incredibly easy for me to swap between different prefix versions because I didn't have to create multiple collections just to test a new prefix, all it took was a single change in the transformation I had defined.
Combined with a good observability platform like braintrust, I was able to iterate on this experiment extremely quickly.
Subjective Evaluation
When things get a bit more subjective, it's important to look at your data. This is where a good labelling interface comes in handy.
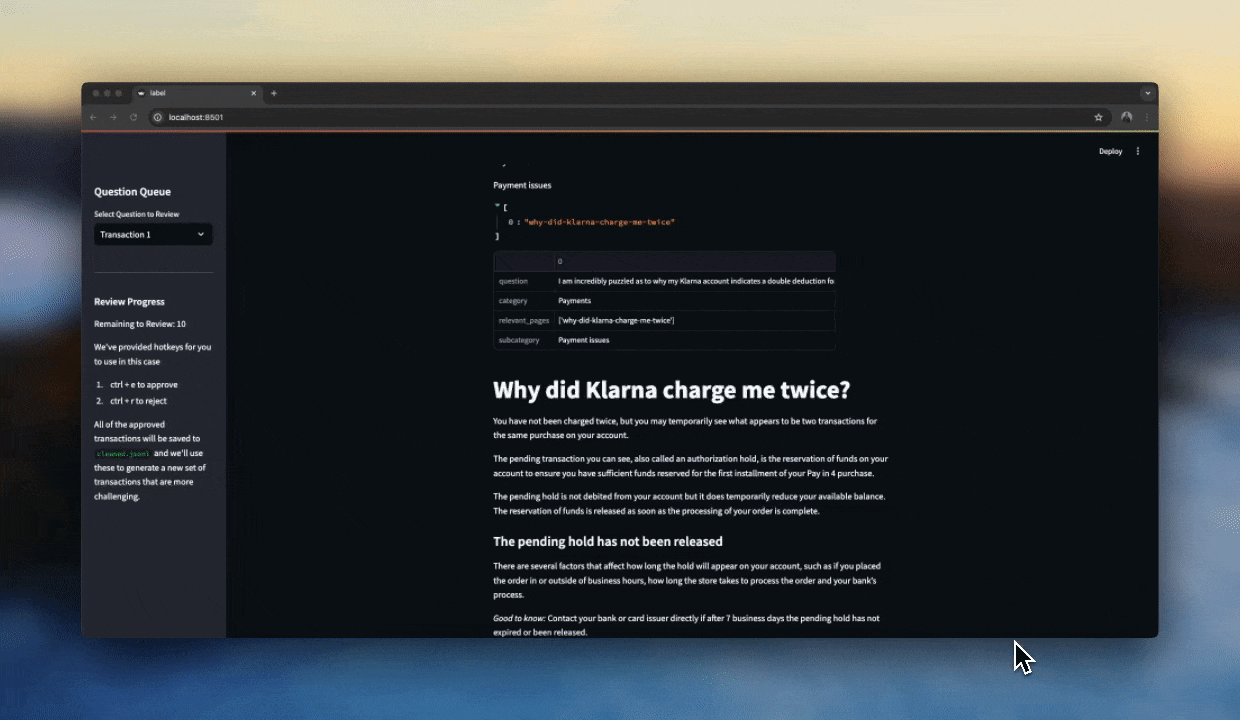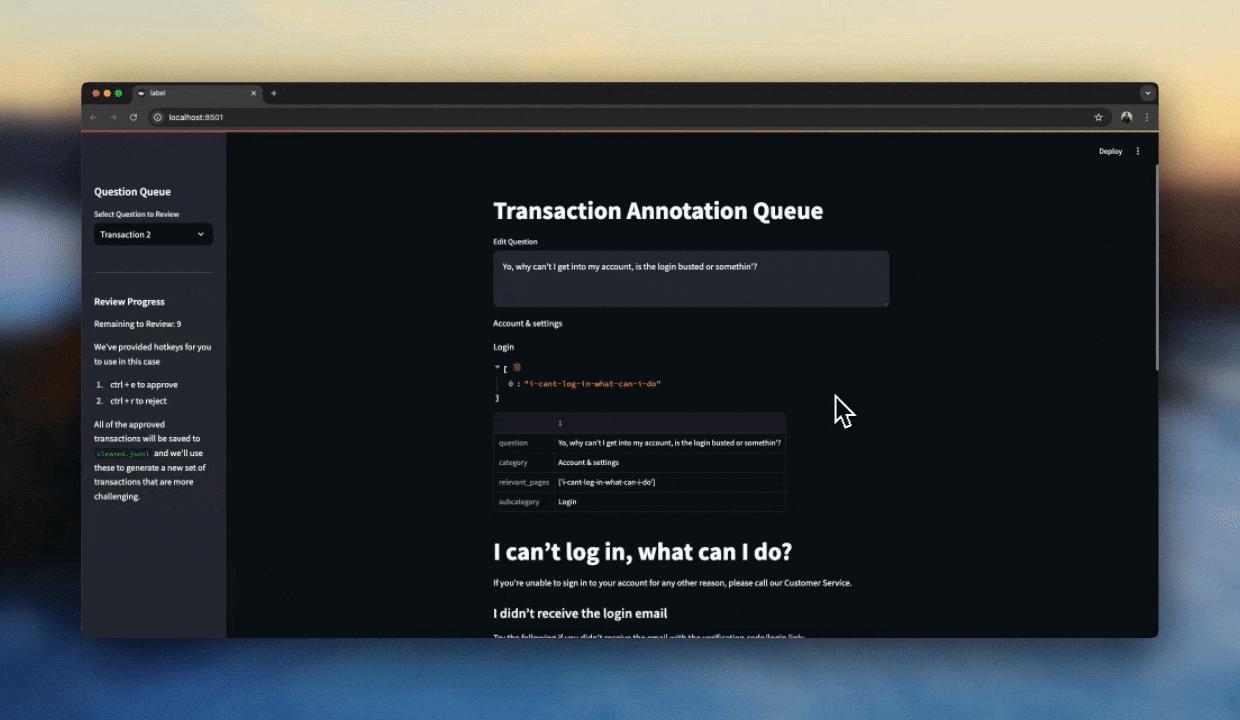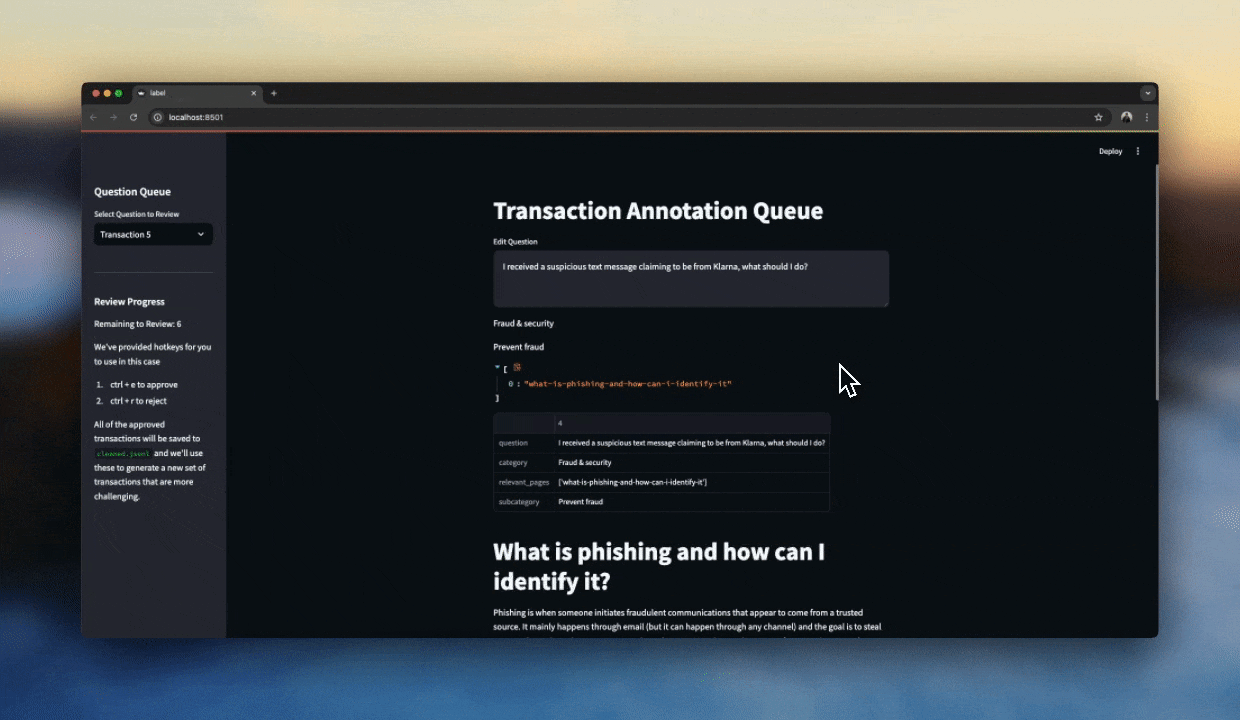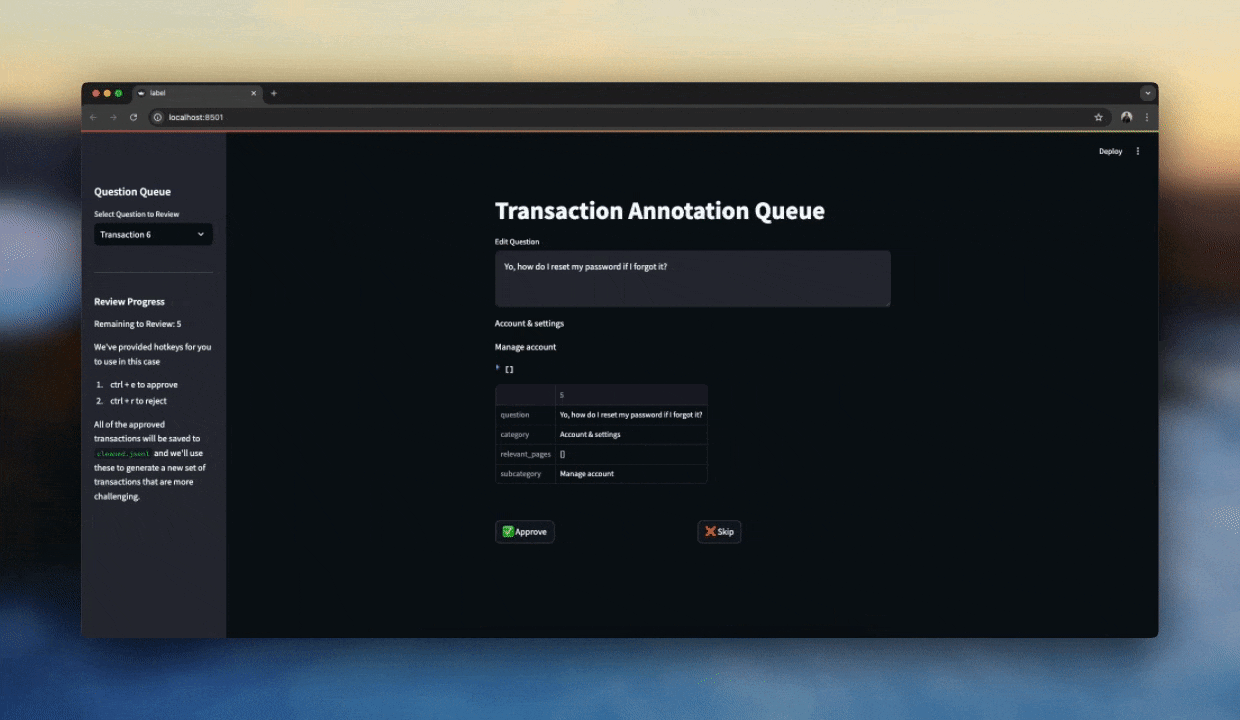
I've found streamlit to be a great tool for this because you can scaffold out a simple interface in a few minutes and iterate as you go. With a decent interface, we can manually label a hundred or so samples reasonably fast and get a good sense for what makes a good response or not.
Whether you're playing with different prompting techniques to get a more relevant answer or a more succint summary, being able to iterate quickly is key here.
Sensitivity Testing
Don't skip validating your results. You need to know if improvements are real or just noise. Basic bootstrapping and significance testing can help you understand if your perceived improvements actually matter.
Random sampling of your data helps validate performance stability and catches edge cases you might miss otherwise. Statistical significance testing ensures you're not chasing improvements that disappear with different data selections.
Key Takeaways
It's not always easy to be systematic when experimenting with LLMs. I'm definitely guilty of jumping straight to a complex prompt and then wondering why my results aren't better, many many times over. But, being clear and mindful about what we're working with and then building good infrastructure around it can be a game changer for your experiments.
Adding even a small step like sensitivity analysis will help you to run your experiments more efficiently and get more reliable results.
Practice makes perfect and the more you do it, the better you'll get at it. It's definitely something I'm working very hard on improving at and I hope that these tips helped you to get a bit better at it.